
Comparing Power BI and Excel: What’s the Best Business Analytics Tool?
Azure Synapse Analytics (Limitless Analytics) became generally available to the public on Dec 3, 2020, and it has been booming in the market since then. So why is that? What did it bring new to the market? In this blog, I will try to give a brief discussion on synapse analytics and its one model Dedicated SQL Pool while focusing a bit more on Serverless SQL Pool, also called Synapse SQL or SQL On-Demand.
Related Blogs
Load Excel Spreadsheets to Structured Databases with Azure Data Factory: Step-by-step
Power BI Data Sources: A Detailed Look at Loading Your Data Into Power BI
How is Synapse Analytics Different From Azure Data Factory?
Synapse is a single managed service that has everything built into one workspace (data integration pipelines, data lake, data warehouse, spark pool, data transformation, Power BI, and machine learning capabilities) which makes authentication and data transfer between the services super easy. With Synapse, Storage and Compute, these are separate which means you pay separately for each.
What is the Difference Between a Dedicated SQL Pool and Serverless SQL Pool?
Synapse has two consumption models – Dedicated SQL Pool where you provision a server based on your needs and you get the ability to pause, resume and scale in/out based on your requirements. On the other side, you have Serverless SQL Pool where you do not need to provision a server, you use the built-in server created and managed by Microsoft and pay for computing based on the requirement of the query. One of the key differences in the models is the architecture Dedicated SQL Pool uses Massively Parallel Processing (MPP) that distributes the query among the nodes and DMS to share the data between the nodes whereas no data is shared in Serverless SQL Pool. Dedicated SQL Pool uses Distributed Query Processing Engine where the queries are assigned to different compute nodes along with the data needed to execute the query. There is no data movement between the compute nodes in Serverless SQL Pool.
Despite the drawbacks of Serverless SQL Pool over Dedicated SQL Pool, below are the use cases when Serverless SQL Pool should be used.
When and Why Use Serverless SQL Pool?
1. When you are running low on budget 💰
Any workspace created in Synapse comes with the built-in SQL pool also known as the Serverless SQL Pool. It uses a pay-per-query costing model where you pay for the compute per TB of data processed while executing the query and not for the minimum reserved resources for the compute (dedicated SQL pool). You just pay for the storage of the data.
2. Explore, discover, and analyze the data stored in Azure storage 🗄
With Serverless SQL Pool, you get the ability to query the data stored in the Azure Data Lake, Blob Storage, Spark Tables, and CosmosDB. You do not have to wait to spin up clusters and then query the tables in Spark or load the data from the files to the tables and then query. You just create a linked service (connection to the data lake from your synapse workspace) and use the OPENROWSET function as shown below to read the data from the file. The output is a table-like result. You can also analyze the data from the files using the TSQL queries that are supported by synapse and write back the result to the data lake as a file.
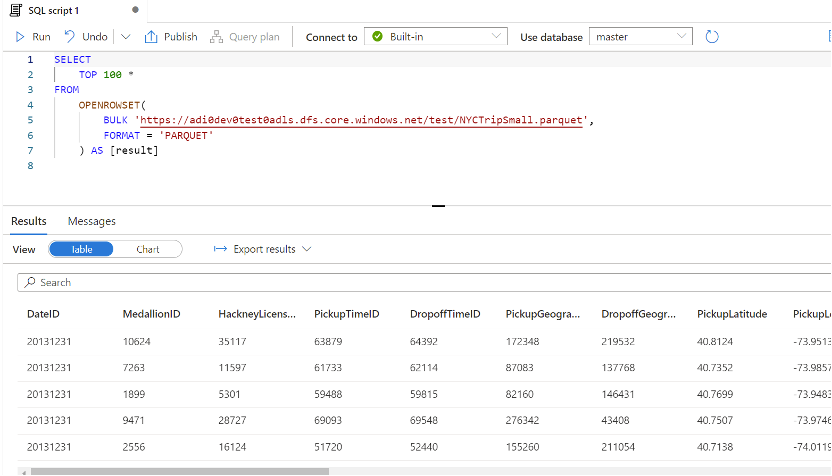
3. Create a Logical Data warehouse 🗃
A Logical Data Warehouse (LDW) is a data management architecture in which an architectural layer sits on top of a traditional data warehouse, enabling access to multiple, diverse data sources while appearing as one “logical” data source to users. You can view or transform the data from different sources without moving or having to know the data.
Advantages of Logical Data Warehouse over the Classic Data Warehouse:
⚙️ Implementing LDW is 90% faster than CDW (Classic Data Warehouse)
🛠 No infrastructure setup is required
💾 No data is stored in LDW as data resides at the source location
📊 No latency of data
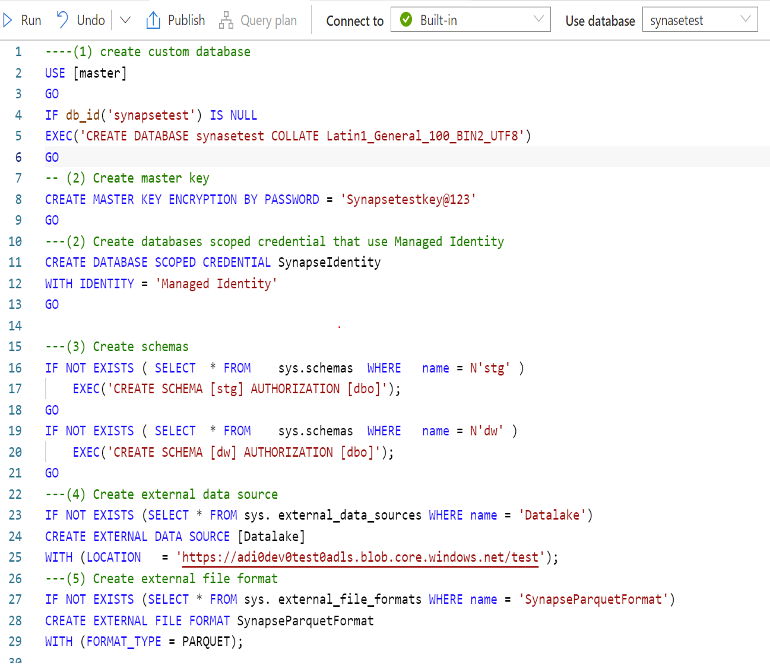
The steps below represent the steps to create a Logical Data Warehouse on top of the files stored in the Azure storage.
- Step 1: Initial Setup
✅ Create a custom database that will hold external tables and views referencing the external data source.
✅ Create database scoped credential that uses synapse managed identity to access the external location.
✅ Create schemas for staging and the logical data warehouse.
✅ Create external data sources pointing to the data lake storage.
✅ Create external file formats.
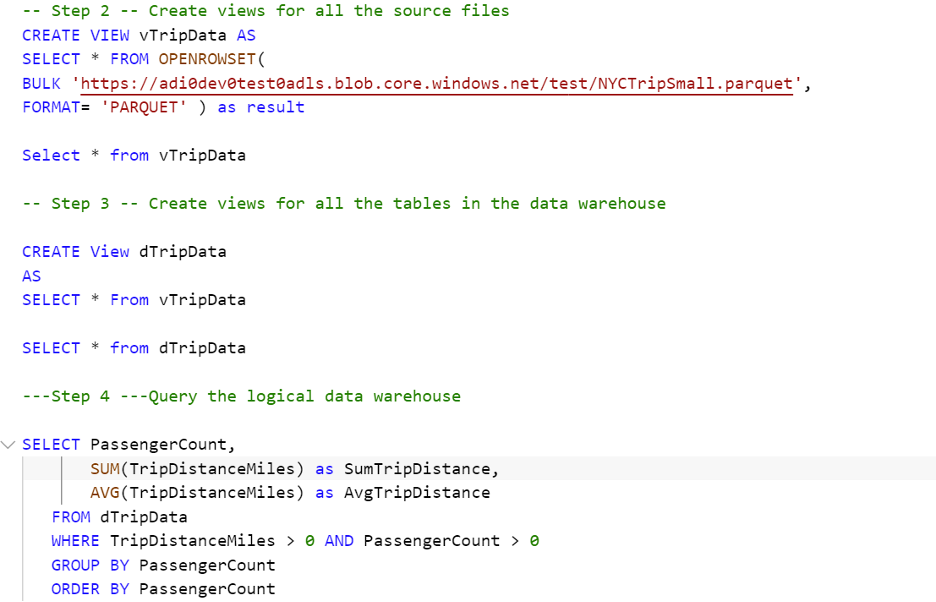
Step 2: Create views for all the source files
Step 3: Create tables and views for Dimensions and Fact Tables
Use CETAS (Create External Table As Select) syntax to create the tables for dimensions and facts and then create views on top of those tables that can be used for querying and visualizing the data.
Step 4: Query the logical data warehouse
4. Create Reports in Synapse PowerBI 📑
Getting the data from Azure synapse analytics in Power BI is still in beta version but it gives us the ability to use the data from the files (logical database) to create reports. It has brought in the capability to use Power BI inside the synapse workspace. With this capability, users can view the reports in the workspace without a Power BI license. You can also create more reports from the dataset pulled into the workspace. Just create a linked service that connects Power BI to synapse and add the existing reports to the workspace.
Bring Your Data Processes Together!
At ProserveIT, we are experts at working with Synapse analytics and have helped our clients to choose and implement the model that best suits their requirements. For more information on how we can help you save money and bring all the processes related to data under the same umbrella, don’t hesitate to give us a shout. Contact Us!
.png?width=850&name=Shipping%20%26%20Inventory%20Reporting%20-%20Power%20BI%20Case%20study%20(5).png)

From the 1980's, when his father used to hand down old computer equipment, to now, Scott Sugar has always had a fascination with technology. The ability to communicate with people, regardless of distance or location, is, in Scott's opinion, one of the best things about tech. With over 20 years of experience in the IT industry, and 17 years at ProServeIT, Scott's areas of expertise include data & analytics, and IT operations, monitoring, and alerting. Scott heads up ProServeIT's Ho Chi Minh City, Vietnam office. He has spent the majority of his adult life in Asia, and speaks 3 languages.



Comments